Il versioning è il meccanismo che abilita più utenti all'editing contemporaneo in geodatabase ArcSDE.
Esso utilizza un modello di concorrenza ottimistica di lock dei dati che, in parole povere, significa che non sono applicati blocchi sulle feature e sulle row durante lunge transazioni.
Il versioning registra e gestisce gli stati delle singole feature e row così come sono modificate mentre preserva l'integrità nel database. Esso è la base per l'accesso multiutente e l'editing simultaneo nei geodatabase Enterprise e non crea copie di dati. Una versione si riferisce ad uno specifico stato del geodatabase. Esso contiene tutti i dataset nel geodatabase ed evolve nel tempo. Gli utenti accedono ai dati attraverso una versione. Dietro le quinte, vengono utilizzate delle query nell'RDBMS per visualizzare o lavorare con uno stato che si riferisce ad un specifico segmento di tempo o per vedere le attuali modifiche del singolo utente. Il versioning permette di gestire complessi workflow di editing che normalmente sono richiesti dai sistemi GIS di fascia Enterprise. Occorre però sottolineare che la maggior parte delle transazioni nei database avvengono nell'ordine dei secondi. Lo stato è l'unità dei cambiamenti (ad esempio una modifica) che è fatta sui dati di un geodatabase; se un cambio è stato fatto esso rappresenta uno snapshot del database.
E' importante però capire perchè le versioni sono importanti: nei geodatabase di tipo enterprise in molti casi molti utenti necessitano di modificare gli stessi dati contemporaneamente. La natura delle relazioni spaziali e della connettività che definisce i dati geografici richiede che le sessioni di editing per dati geospaziali sia dell'ordine delle ore, giorni o settimane. Queste sessioni possono richiedere lunghe transazioni nel DBMS. Inoltre l'utente richiede di poter anche annullare o rifare i cambi apportati, di sviluppare proposte senza intaccare i geodatabase pubblicati e i meccanismi per gestire i cambiamenti nel tempo come i dati e il geodatabase.
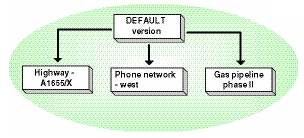
Tutti i geodatabase ArcSDE hanno una versione di default denominata DEFAULT che è di proprietà dell'amministratore ArcSDE. Questa versione esiste sempre e non può essere cancellata. Essa è la radice di tutte le versioni. Normalmente è la versione pubblicata del geodatabase che rappresenta la vista corrente per l'utente finale del geodatabase. La versione di DEFAULT è tipicamente mantenuta e aggiornata nel tempo incorporando in sè le modifiche dalle altre versioni. Come le altre versioni può essere modifica direttamente.
Un geodatabase ArcSDE può avere molte versioni. Una nuova versione (versione figlio) è creata da una versione esistente (versione padre). Quando una versione viene creata è identica alla versione padre. Comunque nel tempo padre e figlio possono divergere a causa delle modifiche effettuate in ogni versione.
Vediamo come creare due versioni figlio della versione di DEFAULT
Innanzitutto occorre versionare i dataset abilitati alle modifiche.

Quando registriamo il nostro dataset nel geodatabase ci viene chiesto se desideramo spostare le modifiche nella tabella base: questa possibilità ci permette di lavorare con l'editing versionato ma supporta anche alcune funzionalità dell'editing non versionato. Quest'ultimo abilita gli utenti ad effettuare modifiche direttamente nelle tabelle base dei geodatabase analogamente ai database classici. Se si seleziona questa funzionalità, essa funziona come l'editing versionato tranne quando si effettuano modifiche alla versione di DEFAULT. Quando si modifica la versione di DEFAULT le modifiche vengono apportate direttamente nella tabella base, anche quando le versioni sono riconciliate e postate (vedremo più avanti questi concetti) alla versione di DEFAULT. Chiaramente sia il modello versionato con spostamento delle modifiche nella tabella base che il modello non versionato presentano delle limitazioni rispetto al modello versionato: ad esempio non è supportata la replica o non tutti i tipi di oggetti possono essere modificati.

Quando modifichiamo il dataset versionato nell'ambiente di editing ogni versione ci sembra abbia una propria copia dei dati. Infatti quando visualizzamo i dati di una versione piuttosto che un'altra il dataset ci può apparire differente. Il dato invece è memorizzato una sola volta del DBMS e, come abbiamo detto precedentemente, dietro le quinte ArcGIS lascia il dataset nel suo originale stato durante l'editing. Le modifiche vengono memorizzate in tabelle associate al dataset dette 'delta table' o tabella A (aggiungi) e tabella D (cancella). Ogni dataset avrà associato una coppia di queste tabelle quando sono registrate come versionate in ArcCatalog.
Ogni versione ha un proprietario, una descrizione, una versione padre, associato uno stato del database e un livello di accesso. I livelli di accesso sono:
- Private: solo il proprietario può vedere e effettuare modifiche;
- Protected: tutti gli utenti possono vedere ma soltanto il proprietario può effettuare modifiche;
- Public: tutti gli utenti possono vedere ed effetture modifiche.
Il livello di accesso predefinito per la versione di DEFAULT è public.
Normalmente è raccomandato di impostare il livello a protected per assicurare che i dati nel geodatabase ArcSDE non siano accidentalmente persi o corrotti. Questo significa che solo l'amministratore ArcSDE può modificare o postare le modifiche alla versione DEFAULT.
Il versioning, come detto, si presta molto bene a gestire complessi workflow così come progetti GIS a fasi (ogni fase è rappresentata da una versione) e modelli a scenari what-if senza intaccare i dataset originali.
Qui potete vedere degli esempi.
Fornisce un framework per gestire sicurezza e assicurare qualità nei dati in editing e supporta archiving e repliche.
Ogni organizzazione può adattare o personalizzare il proprio workflow, visti i moltissimi scenari che il versioning permette di fare.
Il più semplice workflow è avere utenti concorrenti direttamente nella versione di DEFAULT.
Un'altra opzione è creare una versione separata per ogni utente editor. Spesso per proteggere la versione di default si crea una versione di qualità del dato dalla versione di DEFAULT. Questa versione dovrebbe essere gestita da un utente che controlla i dati prima di propagarli alla versione di DEFAULT. Ogni workflow ha pro e contro, pertanto è importante che ognuno utilizzi la miglior strategia atta a soddisfare i propri requisiti nel workflow di business.
Nel nostro esempio creiamo un albero a due livelli (DEFAULT e due figli: VersioneA e VersioneB):
Dal Version Manager selezioniamo la versione padre (in questo caso la versione DEFAULT) e con il tasto destro creiamo la versione versioneA e la versione versioneB.
Visualizzazione del Version Manager dopo che abbiamo aggiunto le due versioni.
Per creare la versione lato programmazione utilizzare l'interfaccia
IVersion2
Qui vediamo un esempio di creazione di due versioni figlio per la versione
versioneQA.
public void CreateChildExample(IWorkspace workspace)
{
IVersionedWorkspace versionedWorkspace = (IVersionedWorkspace)workspace;
IVersion2 qaVersion = (IVersion2)versionedWorkspace.FindVersion("versioneQA");
IVersion2 editorAVersion = (IVersion2)qaVersion.CreateChild("VersioneB",qaVersion);
IVersion2 editorBVersion = (IVersion2)qaVersion.CreateChild("VersioneB", qaVersion);
}
Una versione come detto si riferisce ad uno specifico stato del database, un'unità di modifica che avviene nel database. Ogni operazione di modifica eseguita nel geodatabase crea un nuovo stato del database. Un'operazione di modifica è un qualsiasi task o insieme di task (aggiunte, eliminazioni o modifiche) sulle feature o sulle row. I valori di ID dello stato si applicano a qualsiasi modifica fatta nel geodatabase. Inizialmente la versione di DEFAULT punta allo stato 0. Con le modifiche al geodatabase l'ID dello stato inizierà ad incrementarsi. Normalmente l'ID dello stato si incrementa di un'unità per ogni operazione di editing. Comunque, ci sono delle eccezioni: dove l'ID dello stato si incrementa con un valore più grande dell'unità, così ad esempio durante un'operazione di riconcilia.
Facciamo ad esempio 4 modifiche a due feature class accedendo alla versione di default.
Prima delle modifiche:
Dopo le modifiche (eliminato un poligono, aggiunti due punti e modificato un attributo di un poligono):
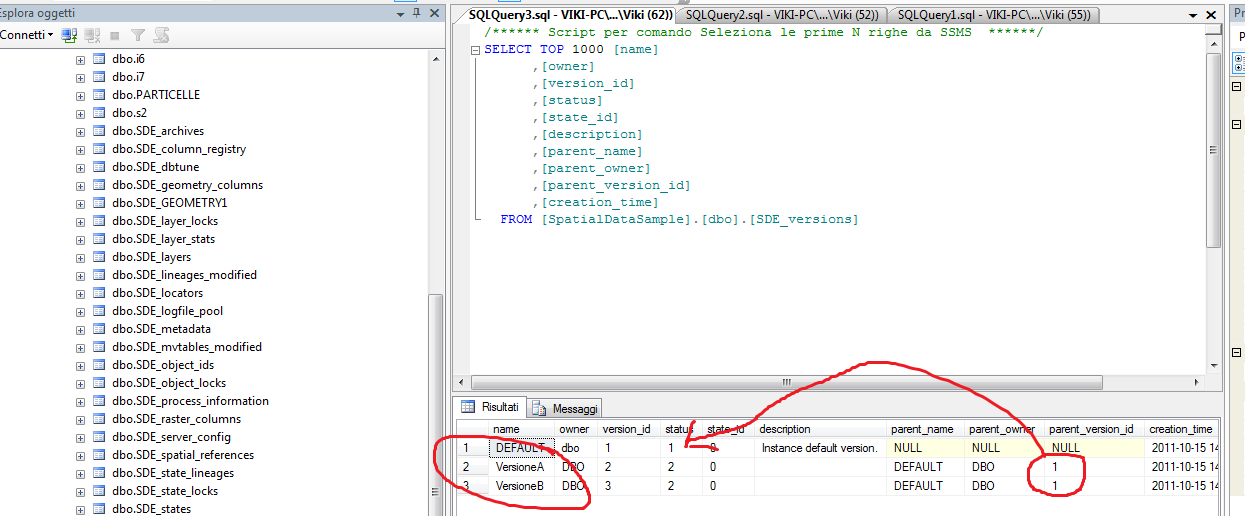
Ora se andiamo a vedere la tabella degli stati:
Come possiamo notare lo state_id ora è 4 (avendo fatto 4 modifiche). I singoli stati dall'1 al 3 sono stati eliminati.
Nella tabella delta D (cancellazione) della feature poligonale possiamo notare due record perchè uno si riferisce all'eliminazione di una feature (con ObjectID 8) con riferimento allo stato Id 4 mentre il primo record è stato aggiunto perchè abbiamo fatto una modifica al poligono con ObjectID 3. La modifica aggiunge un record nella tabella delta A con i nuovi valori e contemporaneamente uno nella tabella D per eliminare il vecchio record.
Ora vediamo uno scenario a due livelli: creiamo due versioni (versioneA e versioneB) dalla versione di DEFAULT. In questo scenario l'ID dello stato crescerà con il numero delle modifiche effettuate nelle sessioni di editing nelle varie versioni. Inizialmente le versioni A e B partiranno con lo stesso ID di stato (stato 0) perchè sono state derivate dalla DEFAULT. Ora l'utente A che opera sulla versione A aggiunge una nuova feature e così l'ID di stato si incrementa di 1. Quando l'utente B inizia una sessione di editing, un nuovo ramo separato è creato dalla DEFAULT per registrare le modifiche. In questo scenario abbiamo ad esempio le seguenti operazioni:
- Utente A aggiunge una feature;
- utente B cancella una feature;
- utente A fonde due feature in una singola;
- utente B aggiunge una feature.
L'ordine di queste operazioni è registrato con il corrispondente ID di stato che rappresenta ogni cambio fatto al geodatabase.
Gli ID di stato nel geodatabase possono essere concepiti come una struttura ad albero. Questa struttura, chiamata diagramma ad albero degli stati, è una mappa logica degli stati in un geodatabase.
Man mano che si modifica nel tempo il geodatabase, una traccia (lineage) degli stati è mantenuta così da identificare tutte le modifiche apportate in una versione. Per determinare la lineage per una specifica versione, si seleziona il percorso più diretto nell'albero degli stati allo stato 0.
ID dello stato a 0 (dalla versione DEFAULT)
Sequenza di editing in multiutenza.
Utente A in versione A: aggiunta di un poligono
Utente B in versione B: cancellazione poligono
Utente A in versione A: fusione di 2 poligoni
Utente B in versione B: aggiunta di un poligono
Con il GDBT possiamo visualizzare l'albero degli stati per questa sequenza di editing
Qui vediamo le due lineage delle due versioni:
Le relazioni padre-figlio possono essere derivate dalle lineage dello stato. Entrambe le versioni A e B fanno riferimento al loro nuovo stato 3 e 4 a differenza della DEFAULT e la loro lineage contiene l'ID dello stato al quale riferisce la DEFAULT ovverosia lo stato 0. La lineage della versione A è 3,1,0 mentre quella della versione B è 4,2,0 mentre la DEFAULT punta all'ID dello stato 0.
Ciò significa che la DEFAULT è una versione antenata alle versioni A e B. Mentre la versione DEFAULT è la versione padre per le versioni A e B.
Tutte le versioni che esistono nel geodatabase ArcSDE possono essere viste nel Version Manager ad esclusione di quelle marcate private che sono solo visibili dai loro rispettivi proprietari.
In questa finestra di dialogo possono essere create e cancellate. Come precedentemente detto, è importate implementare la strategia di workflow che si adatti meglio al proprio business poichè la complessità della gestione delle versioni cresce in base al numero di versioni create.
Le modifiche apportate in una versione rimangono isolate in quella versione fino a quando il proprietario non decide di fonderle con un'altra versione. L'eccezione riguarda il cambio di schema di un dataset (ad esempio aggiunta di un campo in una tabella): questo cambio sarà applicato a tutte le versioni.
Il compito di fondere in modo appropriato le varie versioni si ottiene in ArcGIS grazie a due operazioni: il reconciling e il posting. Queste due operazioni in genere si eseguono l'una dopo l'altra (per esempio il reconciling seguito dal posting) per combinare le modifiche da una versione all'altra.
Reconcile
L'operazione di reconciling è il primo passo per fondere le modifiche tra due versioni. In questo processo le modifiche di una versione antenata (chiamata versione target) sono portate nella versione che è in modifica in una sessione di editing di ArcMap (chiamata versione edit). Una versione target può essere una qualsiasi versione nella lineage della versione che si sta modificando. Ritornando all'esempio precedente, sia la versione A che la versione B possono riconciliare con la DEFAULT perchè entrambe hanno nella loro lineage lo stato con ID 0 che è puntato dalla DEFAULT. Il processo di reconciling fonde le modifiche dalla versione target alla versione edit.
Per eseguire un'operazione di reconcile ci può essere solamente un utente a modificare la versione di edit. Dal momento che una versione mette tutti gli oggetti versionati nel geodatabase, qualsiasi feature modificata nella versione target verrà inserita nella versione di edit. Dal momento che la maggioranza di queste feature non si troverà in conflitto, si inseriranno senza problemi nella versione di edit. Ad esempio: se un poligono fosse aggiunto alla versione target dopo il processo di reconcile, il poligono apparirebbe anche nella versione di edit. L'utente potrebbe allora decidere se salvare o meno le modifiche nella versione di edit.
Ad un livello concettuale, un processo di reconcile comporta l'unione di modifiche relative ad un ramo dell'albero degli stati con un altro ramo.
Riprendiamo l'esempio precedente: dalla versione B eliminiamo un poligono.
Riconciliamo e postiamo con la versione antenata (DEFAULT):
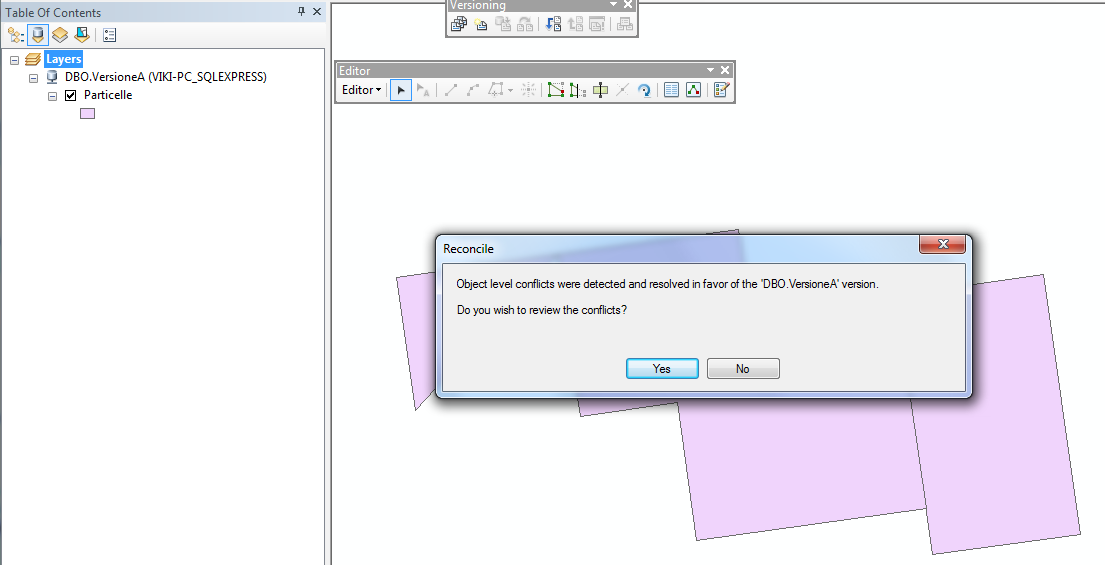
Ora passiamo alla versione A: se riconciliamo con la versione DEFAULT scatta il conflitto perchè lo stesso poligono eliminato nella versione B e propagato alla versione DEFAULT esiste nella versione A.
Nella finestra di dialog Conflits possiamo gestire i conflitti alfanumeri e geografici.
Il processo di reconcile può essere implicito od esplicito.
Implicito: un'operazione di reconcile è implicita quando ci sono diversi utenti che modificano la stessa versione. Ogni utente mantiene il suo ramo per la durata della sessione di editing. Quando un utente cerca di salvare le modifiche della sua sessione avviene un'operazione di reconcile per mettere le modifiche al ramo dell'utente nel ramo al quale si riferisce la versione. Con più utenti in una versione, ogni volta che si salvano le modifiche viene eseguito il processo di reconcile. Non si può scegliere quando esso avviene: succede sempre quando si salvano le modifiche.
Esplicito: Quando si esegue un'operazione di reconcile tra diverse versioni, un utente sceglie quando eseguire il processo di reconcile. Questo è diverso dal processo implicito, che avviene quando si salvano le modifiche. Indipendentemente dal tipo di reconcile, il meccanismo è lo stesso.
La differenza tra processo implicito ed esplicito è quando avviene il processo di reconcile e come vengono specificate le opzioni di individuazione del conflitto.
Possibili conflitti durante il reconciling
In alcuni casi, una piccola percentuale di feature ed oggetti può essere in conflitto quando si confrontano la versione target e la versione edit. I conflitti possono scattare in due scenari di editing:
- quando la stessa feature è aggiornata in entrambe le versioni (target e edit);
- quando la stessa feature è aggiornata in una versiona e cancellata nell'altra.
In pratica, i conflitti non scatteranno frequentemente per la maggior parte dei processi di reconcile, perchè in molti workflow di business, le versioni tipicamente rappresentano differenti progetti con aree geografiche distinte. Pertanto la probabilità che avvengano dei conflitti è rara. I conflitti di solito sorgono quando gli utenti modificano feature in zone di confine.
Quando si eseguono operazioni di reconcile, ArcGIS trova i conflitti in due modi: per object ID o per attributo.
Conflitti per object ID significa che si individua una feature in conflitto quando qualsiasi parte di essa (geometria o attributi) è stata modificata sia nella versione di target che in quella di edit.
Conflitto per attributo significa che si individua una feature in conflitto solo quando lo stesso attributo è stato modificato sia nella versione di target che in quello di edit.
Le regole delle risoluzioni dei conflitti si possono impostare automaticamente sia a favore della versione di target che di edit. C'è anche l'opzione di far risolvere manualmente i conflitti individuati all'utente della versione di edit rivedendo ogni conflitto con la finestra di dialogo Conflicts Resolution in ArcMap.
Si può esaminare dettagliatamente ogni conflitto e l'utente decide se applicare la modifica della versione target, mantenere la modifica della versione di edit o riconvertire la feature a com'era all'inizio della sessione di edit. Dopo la risoluzione di tutti i conflitti (se ce ne sono), il processo di reconcile può considerarsi completato e l'utente può salvare le modifiche e continuare a modificare o procedere con un'operazione di post.
Post
Il post è il secondo passo quando si uniscono le modifiche di due versioni. Questo processo deve sempre seguire un'operazione di riconciliazione. Il processo di post sincronizza la corrente versione di edit con la versione di target. Tutte le modifiche fatte nella versione di edit sono salvate nella versione target facendo entrambe le versioni identiche.
A differenza del processo di reconcile, il posting non può essere annullato una volta che è stato eseguito perchè le modifiche sono applicate ad una versione al di fuori di una sessione di editing.
A questo punto, l'utente della versione di edit ha l'opzione di continuare a fare modifiche in una sessione di editing e poi eseguire un'altro processo di reconcile e di post per sincronizzare le due versioni o semplicemente salvare le modifiche e fermare la sessione di editing nella versione di edit.
Qui potete vedere come riconciliare, ascoltare gli eventi delle versioni, trovare le differenze tra versioni e risolvere i conflitti, tutto via codice tramite gli ArcObjects.
Compress
Nel tempo un'attività di editing in un geodatabase ArcSDE Enterprise accumula centinaia di migliaia di ID di stato (rappresentanti le modifiche memorizzate nella tabella delta). Questo può impattare negativamente nelle prestazioni. Periodicamente l'amministratore ArcSDE deve comprimere il geodatabase ArcSDE rimuovendo gli stati non più riferiti da una versione. Un'operazione di compress può ridurre la profondità dell'albero degli stati e aiuta nelle prestazioni del sistema.
La compressione non rimuove dati che sono accessibili attraverso la lineage della versione, ma solamente i dati non utilizzati. Un'operazione di compress è implementata come una serie di transazioni che rimuovono e rinominano gli stati, il tutto all'interno di una transazione nel database per assicurare che il DBMS possa ripristinare il geodatabase ad uno stato consistente.
Albero degli stati prima di un'operazione di compress.
Albero degli stati dopo un'operazione di compress.